Ten years ago, Netflix started the Netflix challenge. A contest to see if the community could come up with a movie recommendation approach that beat their own by 10%. One of the primary modeling techniques that came out of the contest was a set of sparse matrix factoring models whose earliest description can be found at Simon Funk’s website. The basic idea is that the actual ratings of movies for each user can be represented by a matrix, say of users on the rows and movies along the columns. We don’t have the full rating matrix, instead, we have a very sparse set of entries. But if we could factor the rating matrix into two separate matrices, say one that was Users by Latent Factors, and one that was Latent Factors by Movies, then we could find the user’s rating for any movie by taking the dot product of the User row and the Movie column.
One thing that is somewhat frustrating about coding Funk’s approach is that it uses Stochastic Gradient Descent as the learning mechanism and it uses L2 regularization which has to be coded up as well. Also, it’s fairly loop-heavy. In order to get any sort of performance, you need to implement it in C/C++. It would be great if we could use a machine learning framework that already has other learning algorithms, multiple types of regularization, and batch training built in. It would also be nice if the framework used Python on the front end, but implemented most of the tight loops in C/C++. Sort of like coding the algorithm in Python and compiling with Cython.
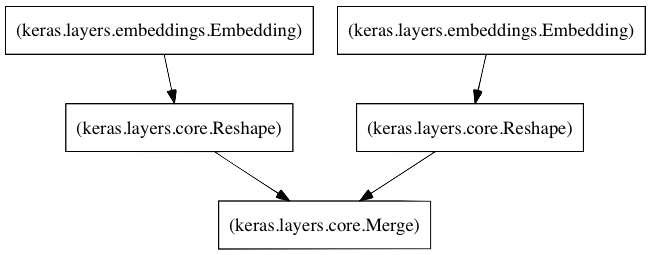
My current favorite framework is Keras. It uses the Theano tensor library for the heavy lifting which also allows the code to run on a GPU, if available. So, here’s a question, can we implement a sparse matrix factoring algorithm in Keras? It turns out that we can:
from keras.layers import Embedding, Reshape, Merge
from keras.models import Sequential,
from keras.optimizers import Adamax
from keras.callbacks import EarlyStopping, ModelCheckpoint
factors = 20
left = Sequential()
left.add(Embedding(numUsers, factors,input_length=1))
left.add(Reshape(dims=(factors,)))
right = Sequential()
right.add(Embedding(numMovies, factors, input_length=1))
right.add(Reshape(dims=(factors,)))
model = Sequential()
model.add(Merge([left, right], mode='dot'))
model.compile(loss='mse', optimizer='adamax')
callbacks = [EarlyStopping('val_loss', patience=2), \
ModelCheckpoint('movie_weights.h5', save_best_only=True)]
model.fit([Users, Movies], Ratings, batch_size=1000000, \
validation_split=.1, callbacks=callbacks)
Ta da! We’ve just created a left embedding layerthat creates a Users by Latent Factors matrix and a right embedding layer that creates a Movies by Latent Factors matrix. When the input to these is a user id and a movie id, then they return the latent factor vectors for the user and the movie, respectively. The Merge layer then takes the dot product of these two things to return rating. We compile the model using MSE as the loss function and the AdaMax learning algorithm (which is superior to Sparse Gradient Descent). Our callbacks monitor the validation loss and we save the model weights each time the validation loss has improved.
The really nice thing about this implementation is that we can model hundreds of latent factors quite quickly. In my particular case, I can train on nearly 100 million ratings, half a million users and almost 20,000 movies in roughly 5 minutes per epoch, 30 epochs - 2.5 hours. But if I use the GPU (GeForce GTX 960), the epoch time decreases to 90s for a total training time of 45 minutes.